vLLM Semantic Router: Next Phase in LLM inference




Industry Status: Inference ≠ More Is Better
Over the past year, hybrid reasoning and automatic routing have become central to discussions in the large-model ecosystem. The focus is shifting from raw parameter counts to efficiency, selectivity, and per-token value.
Take GPT-5 as an example. Its most notable breakthrough isn’t sheer size, but the introduction of automatic routing and thinking quotas:
- Light queries → Lightweight models: Simple prompts like “Why is the sky blue?” don’t need costly reasoning-heavy inference.
- Complex/High-value queries → Advanced models: Legal analysis, financial simulations, or multi-step reasoning tasks are routed to models with Chain-of-Thought capabilities.
This shift reflects a new principle of per-token unit economics.
Every token generated must deliver value, rather than being treated as sunk computational cost.
Use cases:
- Free-tier users are served by lightweight models, keeping costs sustainable.
- Queries with clear commercial intent — e.g., booking flights or finding legal services — are escalated to high-compute models or directly integrated agent services. In these cases, providers can monetize not only inference but also downstream transactions, turning free usage into a revenue engine.
In these cases, companies like OpenAI can participate in the value chain by taking a commission on completed transactions — transforming free usage from a cost center into a monetizable entry point.
Other leaders are adopting similar strategies:
- Anthropic Claude 3.7/4: blends “fast thinking” and “slow thinking,” with user-controlled toggles.
- Google Gemini 2.5: introduces a thinking budget, giving enterprises fine-grained control over inference costs.
- Alibaba Qwen3: explores instruction-based switching between reasoning and non-reasoning.
- DeepSeek v3.1: pioneers a dual-mode single-model design, merging conversational and reasoning flows.
In short: the industry is entering an era where no token is wasted — and routing intelligence defines the frontier of model innovation.
Recent Research: vLLM Semantic Router
As the industry moves toward hybrid reasoning and intelligent routing, this project zeroes in on the open-source inference engine vLLM.
vLLM has quickly become the de facto standard for serving large models at scale. Yet, it still lacks semantic-level control — the ability to decide when and how to apply reasoning based on the actual meaning of a query, not just its type. Without this capability, developers face an all-or-nothing trade-off:
- Enable reasoning everywhere → higher accuracy, but wasted computation and inflated costs.
- Disable reasoning entirely → lower cost, but accuracy drops sharply on reasoning-heavy tasks.
To overcome this gap, we introduce the vLLM Semantic Router — an intent-aware, fine-grained routing layer that brings GPT-5-style “smart routing” to the open-source ecosystem.
By classifying queries at the semantic level and selectively enabling reasoning, the vLLM Semantic Router delivers higher accuracy where it matters and significant cost savings where it doesn’t — a step toward the principle that no token should be wasted.
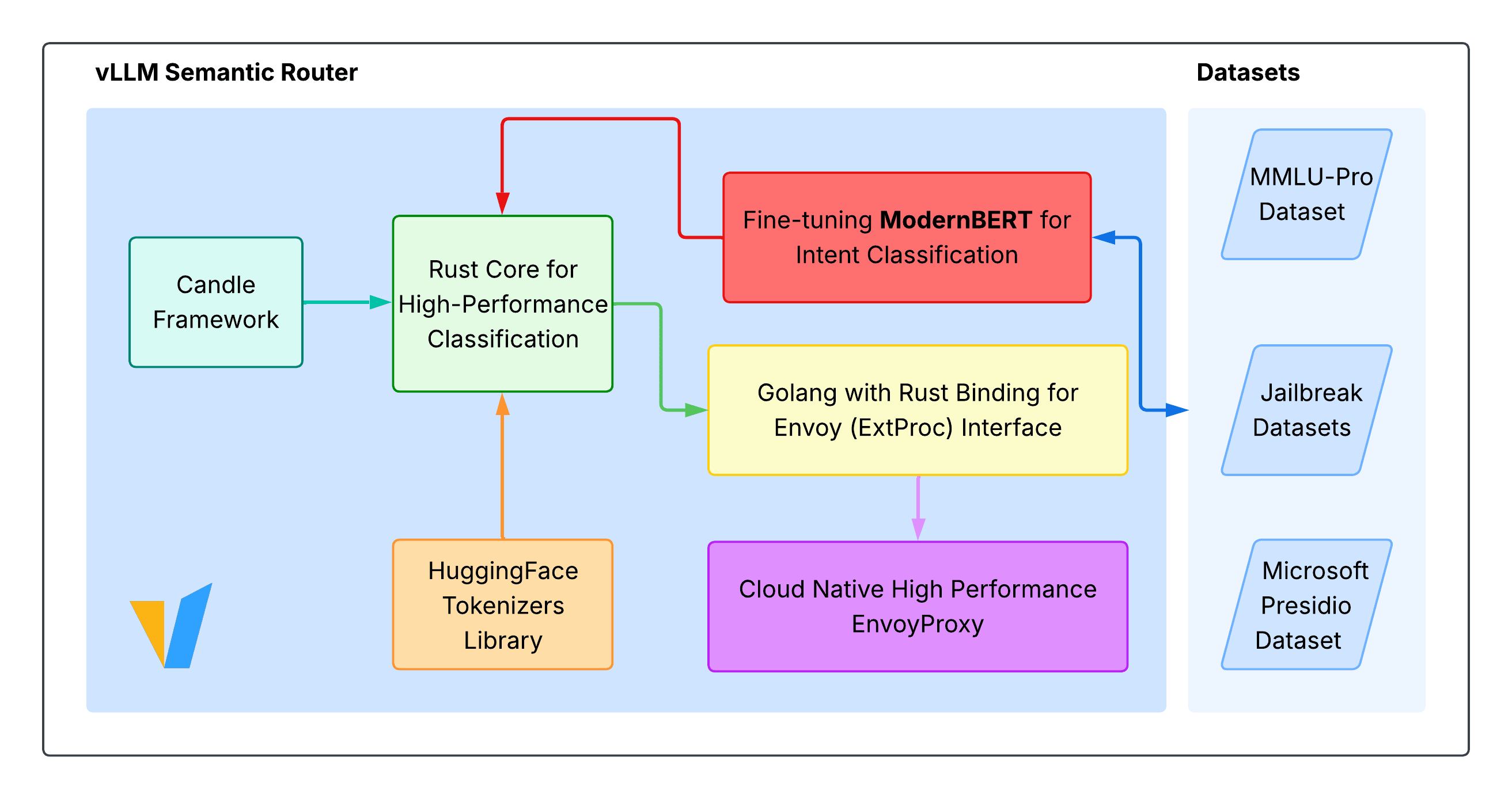
Architecture Design
The vLLM Semantic Router is built to combine fine-grained semantic awareness with production-grade performance. Its design includes four key components:
-
Semantic Classification: A ModernBERT fine-tuned intent classifier determines whether each query requires advanced reasoning or can be handled by lightweight inference.
-
Smart Routing:
- Simple queries → Fast inference mode. Minimal latency and cost for straightforward requests.
- Complex queries → Chain-of-Thought for accurate reasoning. Ensures accuracy on tasks that demand multi-step reasoning.
-
High-Performance Engine: Implemented in Rust using the Hugging Face Candle framework, the engine achieves high concurrency and zero-copy efficiency, making it well-suited for large-scale serving.
-
Cloud-Native Integration: Seamlessly integrates with Kubernetes and API Gateways through the Envoy
ext_procplugin.
Experimental results show:
- Accuracy: +10.2%
- Latency: –47.1%
- Token Consumption: –48.5%
In knowledge-intensive areas such as business and economics, accuracy improvements can exceed 20%.
Project Background
The vLLM Semantic Router is not the isolated result of a single paper but a collaborative outcome of sustained community contributions:
- Originally proposed by Dr. Chen Huamin, Distinguished Engineer at Red Hat, in early 2025 across multiple open-source communities.
- Iterated and further developed by Xunzhuo Liu at Tencent, later contributed to the vLLM community.
- Dr. Wang Chen from IBM Research and Dr. Chen Huamin will present the project at KubeCon North America 2025.
The mission is clear: to serve as an inference accelerator for open-source large models:
- Preserve accuracy while minimizing unnecessary token usage.
- Enable seamless switching between "fast" and "slow" thinking modes without fully enabling or disabling inference.
- Deliver production-ready enterprise integration through native Kubernetes and Envoy support.
The vLLM Semantic Router is therefore not just a research milestone but an essential bridge for open-source AI infrastructure, translating academic innovation into industrial application.
You can start exploring the project at GitHub. We're currently working on the v0.1 Roadmap and have established a Work Group. We welcome your thoughts and invite you to join us!
Future Trends: Cost-Effective, Just-in-Time Inference
The central industry question has shifted from "Can we perform inference?" to "When and how should inference be performed?"
- GPT-5: exemplifies this shift with automatic routing and thinking quotas to align computation with commercial value, enabling monetization.
- vLLM Semantic Router: extends this paradigm to the open-source vLLM engine, enabling semantic aware, low-latency, and energy-efficient inference routing.
Looking ahead, competitive differentiation will hinge less on sheer model scale and more on:
- Performing inference at the right moment with the lowest cost.
- Switching seamlessly between fast and slow reasoning modes.
- Preserving user experience without wasting compute.
The next frontier is intelligent, self-adjusting inference systems — engines that autonomously decide when to think deeply and when to respond directly, without user toggles or rigid rules. This shift marks a new era where inference becomes not just powerful, but context-aware, adaptive, and economically sustainable.
One-Sentence Summary
- GPT-5: Business-driven routing → broad intelligence.
- vLLM Semantic Router: Efficiency-driven routing → sustainable AI.
- Future edge: Performing the right inference at the right time, with minimal computation.